Profiling overhead#
scope-profiler is designed for production HPC workloads where instrumentation must not distort the measurements. This page documents the per-call overhead of each profiling mode.
Benchmark#
The benchmark script (examples/benchmark_overhead.py) times a small
workload function through each profiling mode and subtracts the bare
function-call baseline to isolate the overhead.
python examples/benchmark_overhead.py # save figure
python examples/benchmark_overhead.py --show # display interactively
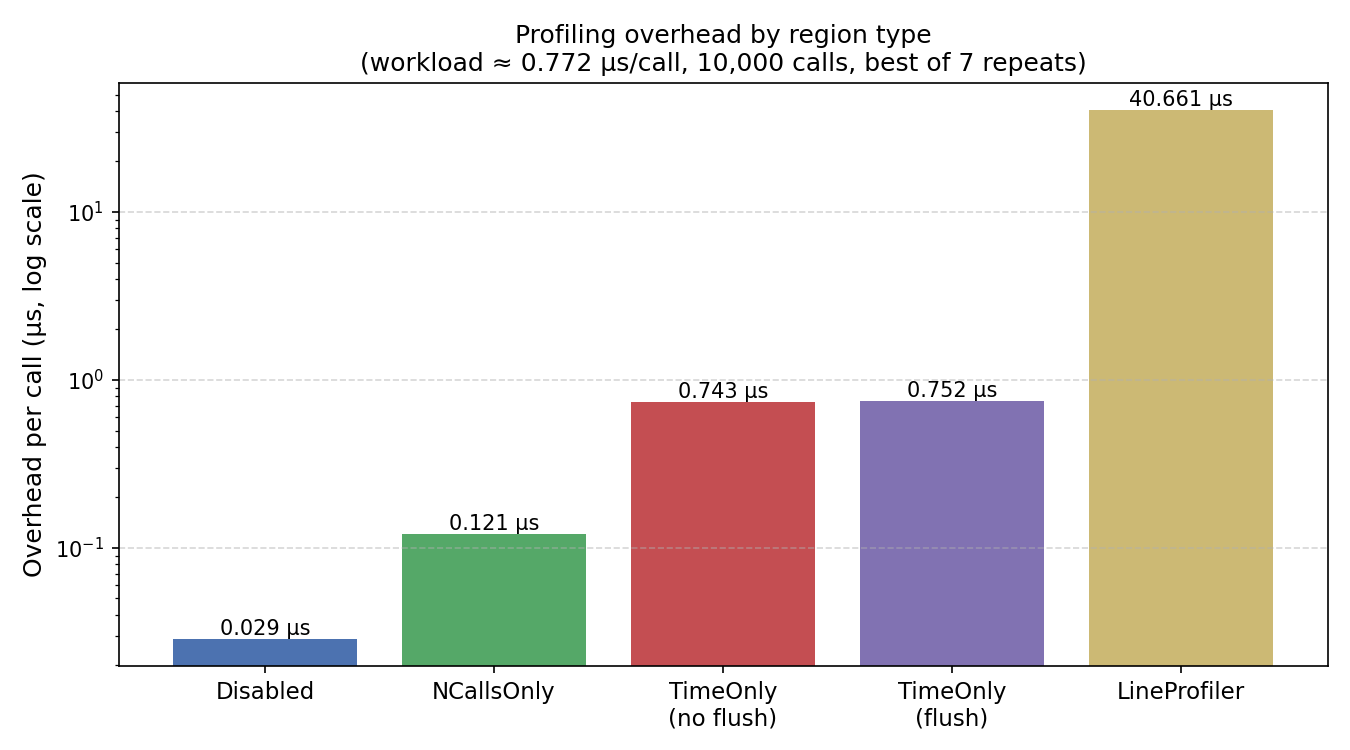
Results summary#
Region type |
Overhead / call |
|---|---|
Disabled |
~0.03 µs |
NCallsOnly |
~0.09 µs |
TimeOnly (no flush) |
~0.74 µs |
TimeOnly (flush) |
~0.76 µs |
LineProfiler |
~41 µs |
(Numbers measured on an Apple M-series CPU; absolute values will vary, but the relative ordering is stable.)
What this means for HPC#
The TimeOnly mode — the default and most commonly used — adds roughly 0.75 µs per instrumented call. In practice:
A 64×64 matrix multiply takes ~36 µs, so the overhead is < 2 %.
A 256×256 matrix multiply takes ~780 µs, giving < 0.1 % overhead.
Typical simulation time steps run for milliseconds or longer, making the overhead unmeasurable.
The profiler can also be fully deactivated at startup
(profiling_activated=False) without removing any instrumentation from
the source code. In this mode the overhead drops to ~0.03 µs — barely
above the cost of a bare function call.
LineProfiler#
The line_profiler mode is intentionally heavier (~41 µs per call)
because it instruments every source line in the profiled function. It
is meant for targeted debugging of individual functions, not for
always-on use in hot loops.
Flush overhead#
The difference between “TimeOnly (no flush)” and “TimeOnly (flush)” is negligible in the benchmark because flushing is amortized: data is only written to HDF5 when the in-memory buffer is full (default: 100,000 events). A single flush takes a few milliseconds but occurs only once per 100k calls, adding < 0.1 µs per call on average.